How Large Language Models Process Text Step by Step
Martha Loppez•29 Dec 25•4 Min Read
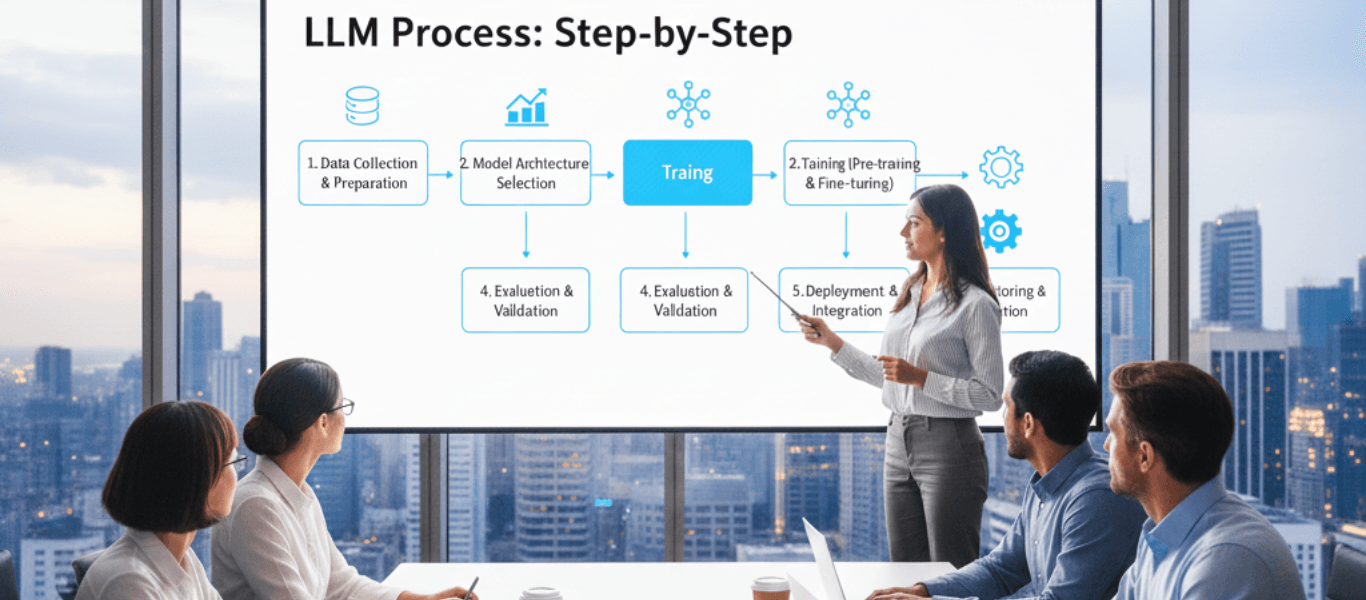
LLM is an abbreviation for Large Language Model. LLMs are the powerhouses of most of the generative tools that you see today. These models handle text in a structured way, convert it into vector embeddings, and then study the relationships within that data. This allows them to produce coherent and contextually relevant outputs.
Large Language Models assist students, writers, and product teams. According to a Hostinger report, approximately 67% of organizations worldwide have adopted large language models (LLMs) to assist with generative AI tasks. This shows how common these models have become, guiding daily work. They can infer intent from patterns and give a helpful output that supports research, planning, and communication.
It is important to understand that LLMs do not learn or update their knowledge while processing user input. Instead, they rely on patterns and relationships learned during large-scale pretraining on vast datasets.
However, what happens inside these models? How do LLMs process data from raw text to clean summaries? This is what we will help you learn in this blog, along with a practical use case of them.
How LLMs Work: The Core Process Step by Step
LLMs convert words into numeric form and then use a transformer network to analyze relationships among those numbers. After this, they move through defined stages. Each stage refines meaning. Together, they let the model summarize, rephrase, or simplify content with predictable results.
The following are the steps LLMs take in processing and simplifying text.
1. Tokenization
The model breaks down the text into smaller units known as tokens. These can be full words, smaller word pieces, or even characters. This helps an LLM read items such as rare terms and names with accuracy. After breaking down the text, they can study each piece with more control.
2. Turning Tokens into Number Form
In this, the tokens are converted into a numeric form called an embedding. This embedding is a simpler form that carries a meaning and a grammatical cue.
Words with similar meaning are placed near each other. This helps the model identify the related words, even if they look different. Along with embeddings, positional information is added so the model understands word order and sentence structure, which is essential for meaning in longer texts.
3. Checking What Links Together
The model compares every token and gives it a score. When a token gets a high score, the model pays more attention to that.
This helps the model detect what is being discussed and predict what comes next. It then analyzes how strongly each token relates to each other to predict which token fits according to the context.
4. Refining Layers
After finding the relevance of context, the model reads through many stacked layers. Each builds on the previous one. The early layer notices which words are related to each other. Later layers refine the context.
Instead of the tokens themselves changing, their internal representations are progressively refined at each layer, allowing the model to form a clearer and more detailed understanding of the message. When each layer has performed its work, the token changes based on the data given by the layers. Bit by bit, the model builds a clear picture of the message. This helps it notice the key points, add details, and give a clear reply.
5. Generation
Generation means producing new text one token at a time. When the model creates a summary or simpler text, it picks each next token based on the context and learned patterns.
At each step, the model selects the next token based on probability distributions learned during training. This steady chain forms clear sentences. You can guide length, tone, and format by giving clear instructions in your prompt.
MapReduce for Long Input
When the text is too long for the model to process in a single attempt, the MapReduce technique is applied. This is an important component for processing and simplifying text, though it is not applied directly by the LLM itself, but at the application level.
In this technique, the full document is split into smaller parts. Each part gets its own summary. These short summaries are then joined to make one final summary. This keeps the main meaning intact while handling long reports or books.
Example of an LLM-Based Online Tool That Processes Text to Create Summaries
You can analyze the working of an LLM through an AI-powered tool, for example, AI Summarizer. It uses LLMs to read and understand the provided text to turn it into clear summaries without losing any key information.
It gives a hands-on experience of how an LLM processes long text for generating summaries. Most online summarizers follow the same procedure. Let’s find out how it works:
Select a long article or report and open the AI summarizer tool. Enter your text into the tool and click on the “Summarize” button. The tool will take a few seconds to give the results, as shown below.

This is how LLMs process and simplify lengthy text into a concise and meaningful text.
Final Thoughts
LLMs work by turning text into small pieces, checking how each piece connects, and then predicting the next piece step by step to form coherent text. After this, they write a simple version that keeps the main sense of the original message.
Rather than copying or memorizing content, the model reconstructs meaning based on learned language patterns, ensuring that the simplified version preserves the original intent.
These models can easily be accessed through web tools like the one shown above to get a clear picture of how they process text. This helps you understand how the process moves from input to output in a smooth way.
