How to Choose the Right RAG Architecture? A Practical Decision Guide
Prakash Donga•6 May 26•8 Min Read
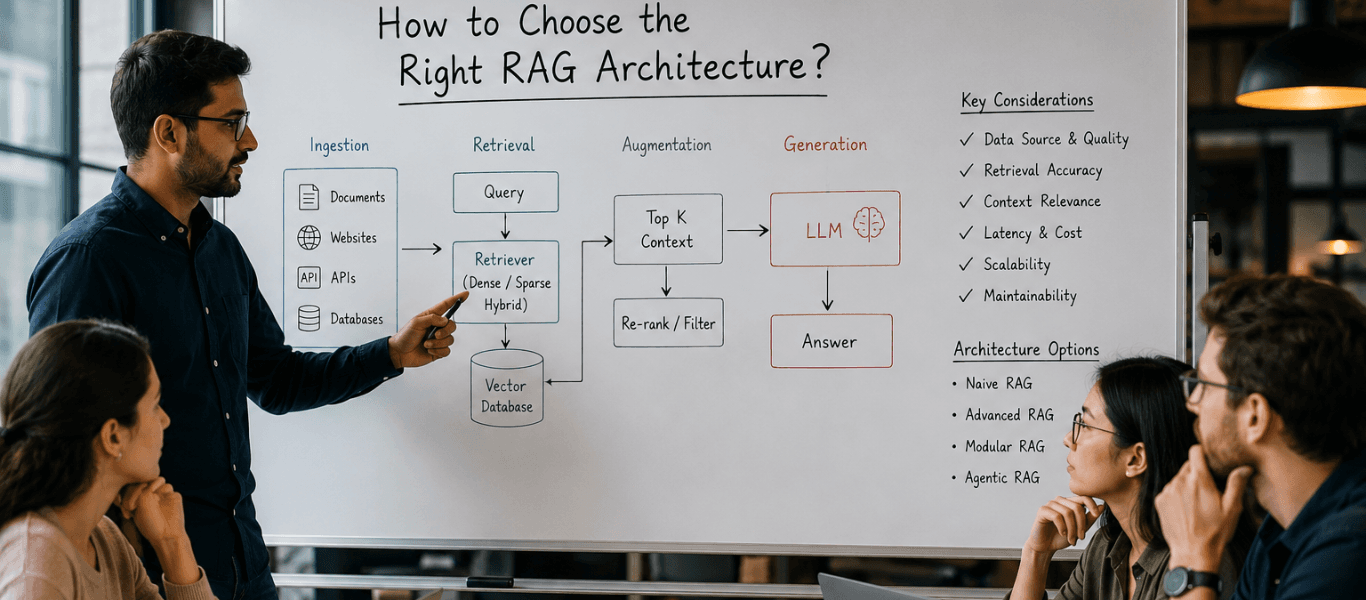
Teams switch models when RAG breaks in production. That's almost never the right fix. The model isn't the problem. The retrieval logic is. Here's how to tell the difference and how to design for it.
Usually, teams will begin with a fairly simple RAG technology stack - i.e., some combination of: vector searches, chunking, and adding a prompt on top of those. The team will see that it works in demos. After deployment, accuracy will drop, edge cases will emerge, and once in production, the RAG system will be unreliable at scale.
Instead of fixing it with prompts, people will instinctively switch models. This usually won't solve the problem.
According to the Gartner report, over 50% of generative AI projects fail to move beyond proof of concept.
RAG is not one pattern (the RAG system). It consists of multiple architectural decisions, and the only difference between a working demo and the RAG system that will work in production is how well those decisions were made.
In this blog, we will break down how to choose RAG architecture using real-world patterns, failure modes, and a practical decision framework that actually works in production.
Why Naive RAG Fails at Scale?
Most RAG failure modes don’t show up in demos; they show up in production.
Everything looks fine: documents are indexed, embeddings exist, and retrieval returns “relevant” chunks. But the answers still miss the mark. That’s because naive RAG system architecture breaks in subtle ways:
1. Irrelevant Retrieval: Semantic search retrieves what’s similar, not what’s precise. This leads to missed edge cases, a common rag retrieval issue, and fixes challenges.
2. Context Overload: Increasing top-k adds noise, not clarity. Too many chunks dilute signal and hurt answer quality, a classic rag pipeline optimization issue.
3. Poor Multi-Hop Reasoning: Simple pipelines assume answers live in one chunk. Real queries don’t. Without a multi-stage RAG pipeline, responses become incomplete.
4. Stale Embeddings: As data changes, embeddings drift. Retrieval still works, just not accurately. This is a hidden reason behind why rag fails in production.
Quick Example
In RAG for customer support systems setup, a refund policy existed in the knowledge base. The user asked: “Can I get my money back after 30 days?”
The system retrieved general policy docs, but missed the exact clause due to a wording mismatch. The answer was vague and unhelpful. The fix wasn’t the model.
It was switching to a hybrid retrieval RAG architecture, combining semantic and keyword search, which immediately surfaced the correct answer.
The RAG Patterns That Actually Show Up in Production

Once you move past naive setups, you start seeing the same few RAG architecture patterns repeat across real systems.
Not because they are trendy, but because they solve actual failure modes.
Here are the ones that consistently hold up in production.
1. Hybrid Retrieval
This is the foundation of most reliable systems today.
A hybrid retrieval RAG architecture combines embeddings with keyword-based search. It fixes one of the biggest gaps in semantic vs keyword search RAG, exact matches.
- Use semantic search for intent
- Use keyword search for precision
This matters in domains like legal, finance, or internal docs, where one missing term changes the meaning. If your queries involve specific product names, policy clauses, contract language, or error codes - hybrid is the baseline, not an upgrade. Start here before anything else.
Skip it only when your queries are purely conceptual and your dataset is small enough that semantic search is already hitting accurately. That is rarely the case once you move past demos.
Real observation: Keyword matching often catches what semantic search quietly misses.
2. Re-ranking Layer
Retrieval isn’t the final step; it’s the first filter.
A re-ranking layer applies RAG reranking techniques to sort retrieved chunks based on actual relevance to the query.
Instead of trusting top-k blindly, you refine it.
- Retrieve 20–50 chunks
- Re-rank to the best 5–10
Reach for this when top-k retrieval is returning the right documents but in the wrong order — or when accuracy has stalled and you've already ruled out chunking and hybrid as the cause. It is a refinement layer, not a foundation. Don't reach for it first.
The trade-off worth knowing: re-ranking adds latency. If your SLA is tight, measure whether the accuracy gain justifies the extra round trip before committing.
Real observation: Top-k retrieval alone is rarely enough for production accuracy.
3. Multi-Stage / Iterative RAG
Some questions don’t have a single-source answer. They require combining information across documents, which is where a multi-stage RAG pipeline or iterative RAG system design comes in. Instead of one retrieval step, the system:
- Retrieves initial context
- Refines the query
- Retrieves again
This allows the model to “think in steps” instead of guessing.
Use this when queries require combining information from more than one document — policy comparisons, multi-hop research, financial analysis, legal review. If a human analyst would need to cross-reference two or three sources to answer the question, single-pass retrieval will always fall short.
Skip it when queries are direct and single-source and when latency is a hard constraint. Iterative RAG is slower by design. For real-time support flows, that cost is often too high.
Real observation: If your queries involve reasoning across sources, single-pass retrieval will break. Build iterative from the start rather than retrofitting it later.
4. Routing / Tool-Augmented RAG
Not all data is the same, and treating it that way causes problems. A tool augmented RAG architecture routes queries to different pipelines based on:
- Data source (structured vs unstructured)
- Query type
- Required precision
For example:
- SQL for structured data
- Vector search for documents
- APIs for real-time data
Use this when your data sources are genuinely mixed — structured tables alongside unstructured documents alongside live APIs. If you find yourself building workarounds to make one pipeline handle two fundamentally different data types, that is the signal to route, not to patch.
Skip it when your data is homogeneous and query patterns are consistent. If 90% of queries take the same path, routing adds overhead for the 10% and complexity that rarely pays off at that ratio.
Real observation: A single pipeline doesn’t scale when your data sources vary.
These patterns aren’t “advanced.” They are what you end up building after naive RAG architecture design stops working. And more importantly, you don’t need all of them. You need the right combination based on your use case.
What Breaks at Each Layer (and How to Catch It Early)?
AI RAG systems don’t fail all at once. They break layer by layer. If you isolate each layer, most issues become easier to spot and fix.
Retrieval Layer
Even with correct data, retrieval often returns loosely related results. This is one of the most common RAG retrieval issues and fixes scenarios.
Fix: Improve your chunking and move to hybrid retrieval (keyword + semantic) for better precision.
Context Layer
Adding more chunks usually makes things worse. The model loses signal, leading to vague outputs, a typical RAG failure mode pattern.
Fix: Focus on compression. Pass only the most relevant, deduplicated context.
Generation Layer
Sometimes the right answer is present, but the model still gets it wrong, classic RAG hallucination despite retrieval.
Fix: Add grounding and validation. Don’t assume retrieval guarantees correctness.
System Layer
What works in testing often breaks at scale. This is a key reason why RAG fails in production.
Fix: Use routing and batching to manage latency, cost, and performance.
Most failures aren’t model problems. They are small issues across layers, and catching them early is what separates a working system from a frustrating one.
Also Read: Top RAG Chatbot AI Systems That are Changing the Game in 2025
How We Approach RAG at SoluteLabs?
Most teams start with a default setup and optimize later. We treat RAG as an architecture problem from day one - before touching a single tool or pipeline - because the decisions made in the first hour usually determine whether the system works in production or just in demos.
Here is what that looks like in practice.
We start by defining the actual query, not the use case.
Not "we need a support bot" — but what specific questions will real users ask, and what does a correct answer actually require? A support bot, a compliance search tool, and an internal knowledge assistant can all be described as "RAG systems." They require completely different architectures.
On a pharmacogenomics platform we built, the queries looked simple on the surface - drug interactions, dosing thresholds, contraindications. But the correct answer often required surfacing a specific clause from a clinical guideline, not the most semantically similar paragraph. That one distinction - precision over similarity - determined the retrieval architecture before we wrote a line of code.
We map the data before we choose the retrieval pattern.
Structured and unstructured data behave differently under retrieval. A system that works well on PDFs will break on database tables if you force both through the same pipeline.
On one internal enterprise build, the knowledge base spanned policy documents, a live product database, and a ticketing system. Three data types, three different retrieval behaviors. We routed them into separate pipelines from the start rather than patching a single pipeline to handle all three. That decision alone eliminated a category of failures we had seen in earlier systems.
We predict failure before the system goes live.
We do not wait for production issues to tell us where the architecture is weak. We ask three questions before any build is finalized: Will retrieval miss key documents due to vocabulary mismatch? Will queries require combining information across multiple sources? Is the underlying data likely to change frequently enough that embeddings will drift?
Each answer changes something about the design. If the answer to question one is yes, hybrid retrieval is in from the start. If the answer to question two is yes, single-pass retrieval is off the table regardless of how clean the demo looks.
We match the pattern to the problem - no defaults.
There is no standard architecture we start from. Some systems need hybrid retrieval and nothing else. Some need a re-ranking layer on top of that. Some need multi-stage retrieval because the queries require reasoning across documents. Some need routing because the data sources are too different to run through one pipeline.
The pattern selection follows directly from the task definition and failure prediction steps above. If those are done well, the architecture choice is usually straightforward.
We build evaluation in before the first retrieval call is made.
This is where most teams go wrong. Evaluation gets treated as a post-launch activity. By then, fixing issues is expensive and the team has already lost confidence in the system.
We define what a correct retrieval result looks like before we write retrieval code. We test retrieval quality independently from generation. We track failure cases from the first test query, not the first production complaint.
Because a RAG system you cannot measure is a RAG system you cannot improve.
Final Words
RAG systems usually fail when the architecture isn’t thought through properly. Retrieval, context, and generation are all connected, and even small gaps in one layer can affect the final output.
What works in testing often doesn’t hold up with real users. Answers become less accurate, edge cases start failing, and performance slows down. That’s why RAG needs to be treated as a system design problem, not just a model integration.
At SoluteLabs, we build RAG systems with real-world usage in mind, from choosing the right architecture to setting up evaluation from day one.
AUTHOR
Prakash Donga
CTO, SoluteLabs15+ years of experience | AI & Product Engineering Prakash Donga leads the technical vision at SoluteLabs, shaping engineering standards and driving product innovation. With extensive experience in AI and product engineering, he guides teams in building secure, scalable systems designed to solve real-world business challenges.How to Choose the Right RAG Architecture? A Practical Decision Guide
